리눅스에서 인식 가능한 USB 카메라를 통해 모션 인식을 해보고, 해당 이미지를 Google Cloud의 ML Engine을 통해 이미지를 판별해보는 과정을 정리했다. 여기에서는 GCP의 Vision API(Face Detection), AutoML(모델링 생성), ML Engine(실제 데이터를 검증)하는 서비스를 사용했다.
1. 준비 단계
목적은 집에 카메라가 모션을 감지해서, 그때 이미지를 GCP의 ML Engine에 보내서 그 이미지의 LABEL이 무엇인지를 판별 한다.
Motion 패키지 : sudo apt-get install motion
GCP Vision API, AutoML, ML Engine 사용
이미지 준비 : 데이터(이미지)는 아들 사진으로 대략 20장 정도를 가지고 Machine Learning에 적용할 생각이다. (사진은 아들 초상권(?)을 위해 블러 처리)
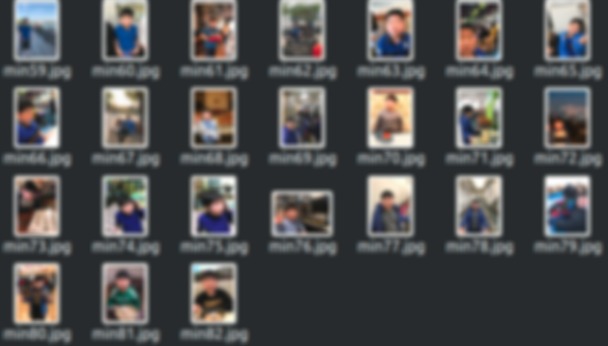
2. 이미지 가공 (Crop)
ML에서 해당 이미지를 Label하기 위해서 위의 이미지에 있는 얼굴 부분들만 Crop이 필요하다. 그래야지 보다 정확하게 Machine Learning을 돌렸을 때 정확한 값이 나온다.
얼굴만 잘라내는 방법은 그냥 자를 수도 있지만 Google Cloud Platform의 Vision API를 사용해서 얼굴의 좌표를 가져올 수 있다.
위의 이미지는 GCP내의 Bucket에 올려두고, Vision API를 호출하여 얼굴을 Detect해본다.
코드를 작성해서 할 수도 있지만, 간단하게 얼굴 좌표만 받아와서 이미지를 잘라낼 용도이기 때문에 curl을 통해 API를 호출해본다. 방법은 아래 링크를 참조하자
https://cloud.google.com/vision/docs/using-curl
우선 API에 던질 JSON을 아래와 같이 만든다.

그리고 아래 명령어를 통해 API를 호출한다. 호출하기 전에 Vision API Key를 생성한다..
curl -v -s -H "Content-Type: application/json" https://vision.googleapis.com/v1/images:annotate?key=<API_KEY> --data-binary @<sample.json>
샘플 코드는 여기에서 볼 수 있다
위의 curl을 수행한 결과는 아래와 같이 나온다.

Curl로 호출해서 해당 좌표를 받아서 이미지를 얼굴만 Crop을 해야 하기 때문에 어쩔수 없이 python으로 코딩을 했다.
github.com/thkang0/…
이렇게 하면 아래와 같이 얼굴만 자르게 된다. 이제 이 이미지를 가지고 Google Cloud의 AutoML로 Training을 할 예정이다.
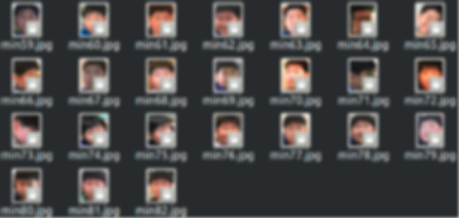
3. AutoML
Google에서 제공하는 Machine Learning 서비스 중의 하나인 AUTOML은 크게 어렵지 않게 Machine Learning의 모델을 만들 수 있게 서비스를 제공한다. 아직 알파 버전이긴 하지만 곧 나올 예정이니 머신 러닝 모델링에 관심 있는 사람들은 지켜볼만 할 것 같다.
https://cloud.google.com/automl/
Datasets을 생성

Google Cloud Storage에 image를 업로드 한다. AUTOML은 특정 Bucket(vcm으로 끝나는..)에 있는 이미지만 가져오는 듯 하기 때문에 해당 Bucket에 이미지를 업로드 하고, 이미지와 Label을 아래와 같이 맵핑한 CSV를 Bucket에 업로드 한다. Comma로 JPG와 Label을 구분한다.

CSV를 위와 같이 만든 후 AUTOML 화면에서 Upload한다.

성공적으로 업로드가 되고 나면 LABEL 항목에서 정의된(라벨은 DAD, SON 두개로 정의) 것을 확인 할 수 있다.
입력된 이미지와 라벨을 이용하여 Train을 시켜볼 수 있다. AUTOML의 경우 Base Model은 공짜(Free), Advanced Model은 550$이다. 테스트를 해본결과 Advanced Model의 적중율이 좀더 높아 보이지만, 우선 공짜인 Base Model로 Training을 해 본다. 총 이미지는 48개가 업로드 되어 있다.
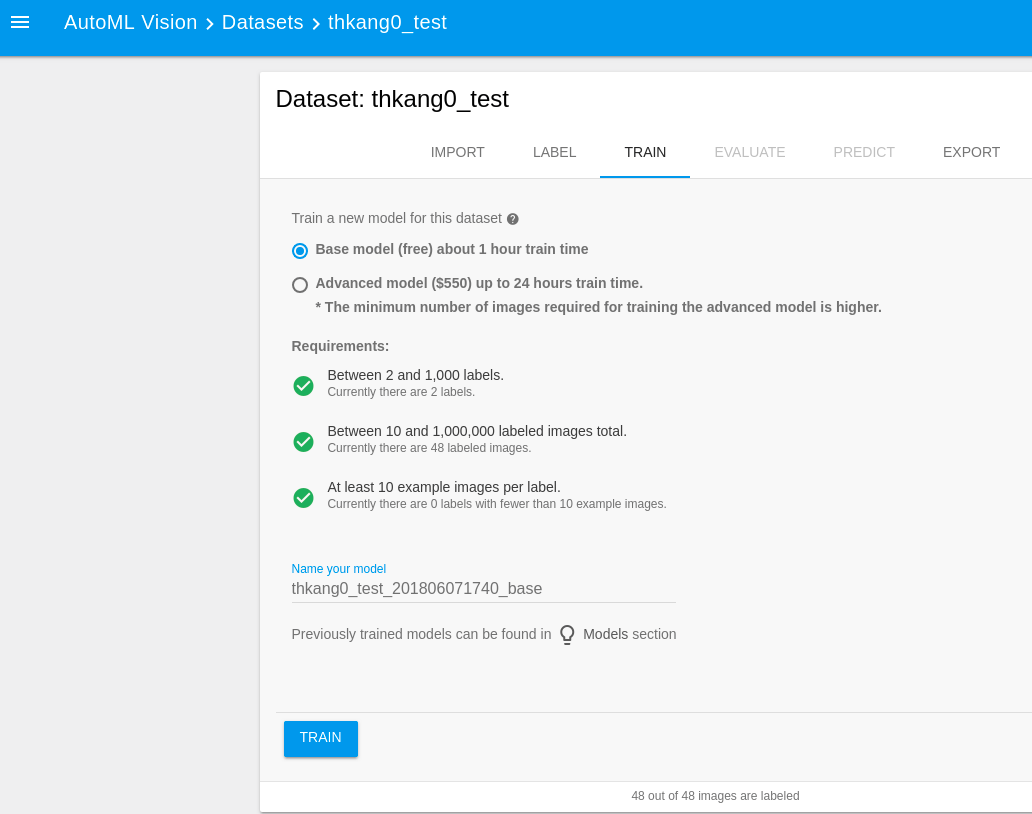
Training이 끝나고 나면 이제 생성된 Model을 통해 예측(Predict)를 할 수 있다. Evaluate항목에서 아래 메세지는 업로드한 이미지가(48개) 너무 적어서 나는 경고이며, 정확도를 높이기 위해서는 보다 많은 데이터가 필요하다. (100개 이상)

Predict는 AUTOML에서 Online으로 할 수도 있고, gcloud 명령어나 ML API를 연동해서 할 수도 있다. 이것은 Training된 모델이 결국 GCP내의 ML Engine의 Model로 생성되기 때문이다.
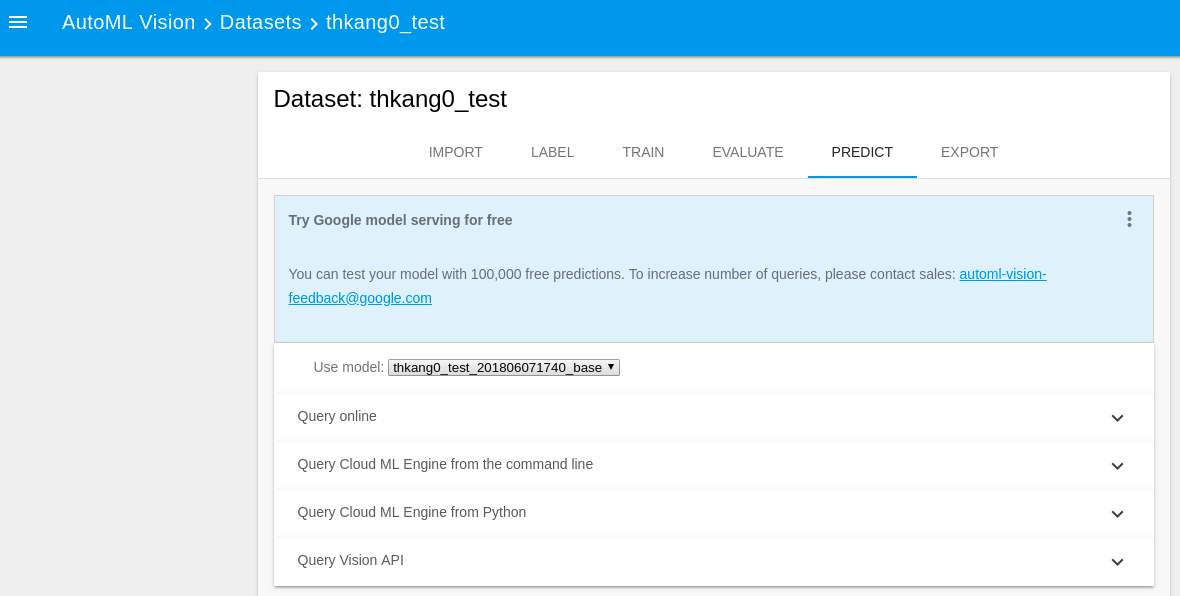
GCP내에서 위 모델은 ML Engine Model에서 찾을 수 있다.
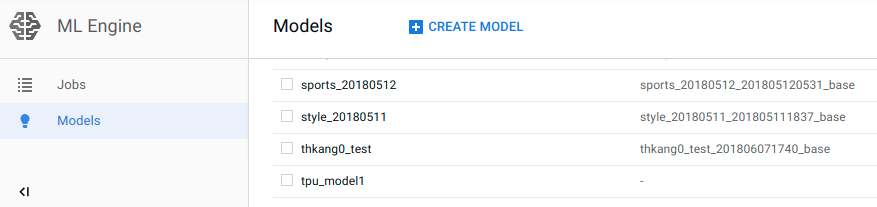
Predict을 Online에서 파일을 업로드 하고 돌려보면 혼자 있는 사진은 잘 판별하는 듯 하나 여려명이 있는 경우에는 보다 많은 데이터가 필요해 보인다.

Python으로 수행하게 되면 아래와 같은 결과를 json 형식으로 리턴해준다.
$ python predict.py ~/photo6111533541184612377.jpg tribal-mapper-199302 thkang0_test thkang0_test_201806071740_base
{u'predictions': [{u'labels': [u'dad', u'son', u'--other--'], u'key': u'0', u'scores': [0.14696481823921204, 0.8529432415962219, 9.195350139634684e-05]}]}
4. Motion Detection
환경은 Ubuntu 18.04에 USB WebCam (Creative Technology Ltd. Live! Cam Chat HD VF0790) 이라는 카메라를 연결했다. 연결되면 아래 처럼 USB에 웹캠이 인식된다.
$ lsusb
Bus 001 Device 003: ID 041e:4097 Creative Technology, Ltd
설치는 sudo apt-get install motion 으로 설치하면 된다.
Motion에 관련된 설정은 아래 github을 참조하자.
5. 프로세스
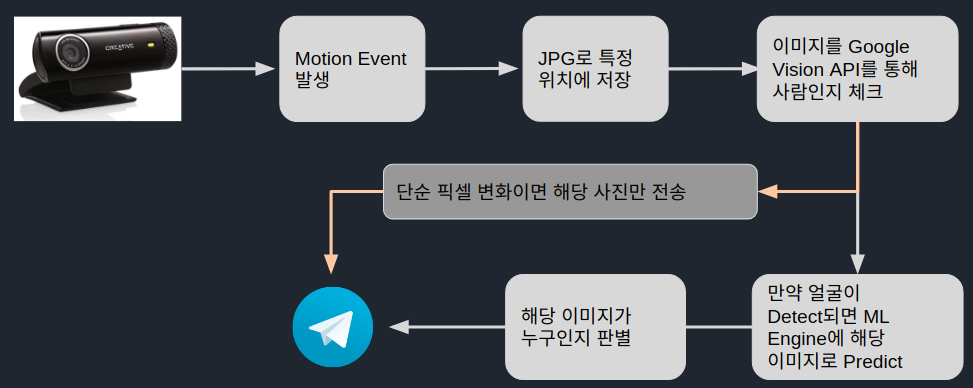
6. 결과
데이터 셋이 부족(20장 정도로는 부족)해서 결과가 그렇게 정확하게 나오지는 않았다. LABEL이 잘못 판단되어 아들 얼굴이지만 Dad로 나오는 경우도 있었고, 캠 해상도가 낮아 얼굴 인식이 제대로 되지 않기도 했다. 참고로 AutoML의 경우 Advanced로 모델링을 만들면 좀 더 좋은 결과가 나온다고 한다. 하지만 비용이 들기 때문에 신중히 적용할 필요가 있다.
참고로 vision api를 payload로 호출 시 이미지는 4MB 이하여야 하고 ML엔진의 경우에도 이미지는 1.5MB 이하가 되어야 한다. 넘으면 아래와 같이 에러가 난다.
Data는 최소 100장은 있어야 좀 더 정확히 결과가 나올 것 같다.
Motion을 detect해서 텔레그램 까지 연동되는 소스는 아래에 올려두었다.
https://github.com/thkang0/motion_alert

