반응형
타이타닉 데이터 분석 및 머신러닝 적용 목차
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #1 데이터 내용 및 객실등급(Pclass), 성별(Sex)확인
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #2 나이(Age)와 탑승위치(Embarked) 확인
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #3 형제자매,배우자(SipSp) 확인
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #4 데이터 정리 및 Feature Engineering
- [머신러닝 기초] 타이타닉 생존율 데이터 가공 - Machine Learning을 위한 데이터 처리 방법
- [머신러닝 기초] 타이타닉 생존율 모델링 - Predictive 모델링
- [머신러닝 기초] 타이타닉 생존율 분석 - Cross Validation
- [머신러닝 기초] 타이타닉 생존율 모델링 최적화 - 앙상블(Ensemble)
Age에 Null Data가 많은 것을 이전에 확인을 했고, 해당 Null Data에 데이터를 임의의 값으로 채워 넣기 보다는 근거에 기반하여 나이의 Null값을 채워넣는다. 이름을 확인해보면 다양하게 존재한다.
data['Initial']=0
for i in data:
data['Initial']=data.Name.str.extract('([A-Za-z]+)\.')
print(data['Initial'])
print(data['Name'])이름에 Mr, Miss, Master, Rev등등 기입이 되어 있는데, 오타일 가능성이 있다고 판단할 수 있다.

Crosstab으로 전체 이름이 어떤 것들이 있는지 확인하고 몇명이 있는지 확인한다.
pd.crosstab(data.Initial,data.Sex).T.style.background_gradient(cmap='summer_r')Dr, Don, MIIe 등등 오타로 보이는 이름들이 보인다.

오타로 보이는 것들을 Mr, Mrs, Miss, Other로 변경한다. 참고로 Master는 Mr로 불릴 정도의 나이가 안된 어린 나이 남자에 대한 호칭이다.
data['Initial'].replace(['Mlle','Mme','Ms','Dr','Major','Lady','Countess','Jonkheer','Col','Rev','Capt','Sir','Don'],['Miss','Miss','Miss','Mr','Mr','Mrs','Mrs','Other','Other','Other','Mr','Mr','Mr'],inplace=True)
#print(data.Initial)
pd.crosstab(data.Initial,data.Sex).T.style.background_gradient(cmap='summer_r')이제 Master, Miss, Mr, Mrs, Other로 이름을 줄여서 분류할 수 있다.
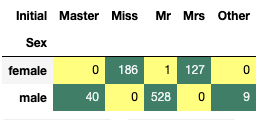
해당 이름별로 나이의 평균을 구해본다.
data.groupby('Initial')['Age'].mean()어린아이는 4살, Miss는 21세, Mr는 32세, Mrs는 35세로 평균을 구할 수 있다.

위 평균값을 이용하여 Age에 Null인 데이터에 평균값을 넣어준다.
data.loc[(data.Age.isnull())&(data.Initial=='Mr'),'Age']=33
data.loc[(data.Age.isnull())&(data.Initial=='Mrs'),'Age']=36
data.loc[(data.Age.isnull())&(data.Initial=='Master'),'Age']=5
data.loc[(data.Age.isnull())&(data.Initial=='Miss'),'Age']=22
data.loc[(data.Age.isnull())&(data.Initial=='Other'),'Age']=46Age데이터에 이제 Null이 있는지를 확인한다.
data.Age.isnull().any()
data.Age.isnull().sum()
이제 나이별로 사망자 수와 생존자 수를 그래프로 확인한다.
f,ax=plt.subplots(1,2,figsize=(20,10))
data[data['Survived']==0].Age.plot.hist(ax=ax[0],bins=20,edgecolor='black',color='red')
ax[0].set_title('Survived= 0')
x1=list(range(0,85,5))
ax[0].set_xticks(x1)
data[data['Survived']==1].Age.plot.hist(ax=ax[1],color='green',bins=20,edgecolor='black')
ax[1].set_title('Survived= 1')
x2=list(range(0,85,5))
ax[1].set_xticks(x2)
plt.show()사망자 중 30대가 제일 많았으며 생존자 중에서는 30대, 20대가 많은 것을 확인 할 수 있다.

이제 factorplot으로 객실과 생존율을 이름별로 확인해본다.
sns.factorplot('Pclass','Survived',col='Initial',data=data)
plt.show()성인남성 중 1등급 객실이 생존율이 높고 기혼여성, 미혼여성 모두 1등급 객실에서 생존율이 높은 것을 확인 할 수 있다.

Crosstab으로 성별, 객실별, 배를 탄곳(Embarked)에서 생존자 수를 확인해본다.
pd.crosstab([data.Embarked,data.Pclass],[data.Sex,data.Survived],margins=True).style.background_gradient(cmap='summer_r')3등급 객실과 S에서 배를 탄 사람의 사망자 수가 가장 높은 것을 확인 할 수 있다.

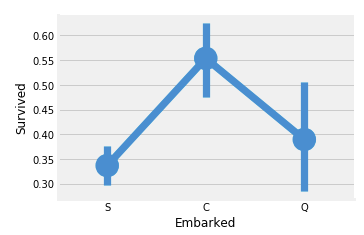
factorplot으로 Embarked와 생존율을 확인한다.
sns.factorplot('Embarked','Survived',data=data)
fig=plt.gcf()
fig.set_size_inches(5,3)C에서 탄 승객의 생존율이 높은것을 확인 할 수 있다.
승선한 곳 별로 승객수, 성별로 승객수, 승선한곳에 대한 생존자 수, 승선한 곳과 객실 등급 별 승객수를 확인한다.
f,ax=plt.subplots(2,2,figsize=(20,15))
sns.countplot('Embarked',data=data,ax=ax[0,0])
ax[0,0].set_title('No. Of Passengers Boarded')
sns.countplot('Embarked',hue='Sex',data=data,ax=ax[0,1])
ax[0,1].set_title('Make-Female Split for Embarked')
sns.countplot('Embarked',hue='Survived',data=data,ax=ax[1,0])
ax[1,0].set_title('Embarked vs Survived')
sns.countplot('Embarked',hue='Pclass',data=data,ax=ax[1,1])
ax[1,1].set_title('Embarked vs Pclass')
plt.subplots_adjust(wspace=0.2,hspace=0.5)S에서 탄 승객수가 가장 많으며 S에서는 남성이 400명 이상, 여성이 200명 정도, S에서 탄 승객의 사망자수가 가장 높으며, S에서 탄 승객들은 3등급 객실에 가장 많이 탄것을 확인 할 수 있다.

객실등급과 생존자를 성별과 승선한 곳에 따라 비교해본다.
sns.factorplot('Pclass','Survived',hue='Sex',col='Embarked',data=data)
plt.show()S에서 탄 승객 중 1,2등급 객실에 탄 여성 승객은 생존율이 높으며, C에서 탄 승객 중 1,2등급 객실에 탄 여성 승객의 생존율이 높은 것을 알 수 있다. Q에서 탄 여성 승객 역시 마찮가지이다.

많은 승객들이 S에서 승선한것을 알 수 있기 때문에 Embarked에 Null인 데이터는 S에서 승선한것으로 채워넣는다
data['Embarked'].fillna('S',inplace=True)그리고 나서 Null Data가 있는지 확인해보면
data.Embarked.isnull().any()
* 해당 타이타닉 notebook은 Kaggle의https://www.kaggle.com/ash316/eda-to-prediction-dietanic분석을 그대로 따라하면서 나름대로 정리한 부분임을 밝혀둔다.
반응형



