반응형
타이타닉 데이터 분석 및 머신러닝 적용 목차
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #1 데이터 내용 및 객실등급(Pclass), 성별(Sex)확인
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #2 나이(Age)와 탑승위치(Embarked) 확인
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #3 형제자매,배우자(SipSp) 확인
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #4 데이터 정리 및 Feature Engineering
- [머신러닝 기초] 타이타닉 생존율 데이터 가공 - Machine Learning을 위한 데이터 처리 방법
- [머신러닝 기초] 타이타닉 생존율 모델링 - Predictive 모델링
- [머신러닝 기초] 타이타닉 생존율 분석 - Cross Validation
- [머신러닝 기초] 타이타닉 생존율 모델링 최적화 - 앙상블(Ensemble)
지금까지 데이터를 정리한 것을 EDA라고 부른다. 이제 머신러닝 모델을 사용하여 생존율을 예측해본다. 아래 7가지의 모델을 사용하여 승객의 생존율을 예측해본다.
- Logistic Regression
- Support Vector Machines(Linear and radial)
- Random Forest
- K-Nearest Neighbours
- Naive Bayes
- Decision Tree
- Logistic Regression
우선 ML package를 Import한다
from sklearn.linear_model import LogisticRegression
from sklearn import svm #Support Vector Machine
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.metrics import confusion_matrix데이터를 Training Data와 Test Data로 분류한다. Survived의 값은 train_Y와 test_Y에 들어갈 수 있도록 한다.
train,test=train_test_split(data,test_size=0.3,random_state=0,stratify=data['Survived'])
train_X=train[train.columns[1:]]
train_Y=train[train.columns[:1]]
test_X=test[test.columns[1:]]
test_Y=test[test.columns[:1]]
X=data[data.columns[1:]]
Y=data['Survived']Radial Support Vector Machines(rbf-SVM)
model=svm.SVC(kernel='rbf',C=1,gamma=0.1)
model.fit(train_X,train_Y)
prediction1=model.predict(test_X)
print('Accuracy of rbf SVM is ',metrics.accuracy_score(prediction1,test_Y))정확도는 84%정도 나온다

Linear Support Vector Machine(linear-SVM)
model=svm.SVC(kernel='linear',C=0.1,gamma=0.1)
model.fit(train_X,train_Y)
prediction2=model.predict(test_X)
print('Accuracy of Linear SVM is ',metrics.accuracy_score(prediction2,test_Y))정확도는 82%정도 나온다

Logistic Regression
model=LogisticRegression()
model.fit(train_X,train_Y)
prediction3=model.predict(test_X)
print('Accuracy of the LogisticRegression is ',metrics.accuracy_score(prediction3,test_Y))정확도는 82%정도 나온다

Decision Tree
model=DecisionTreeClassifier()
model.fit(train_X,train_Y)
prediction4=model.predict(test_X)
print('Accuracy of the Decision Tree is ',metrics.accuracy_score(prediction4,test_Y))정확도는 79%정도 나온다

K-Nearest Neighbours(KNN)
model=KNeighborsClassifier()
model.fit(train_X,train_Y)
prediction5=model.predict(test_X)
print('Accuracy of the KNN is ',metrics.accuracy_score(prediction4,test_Y))정확도는 79%정도 나온다

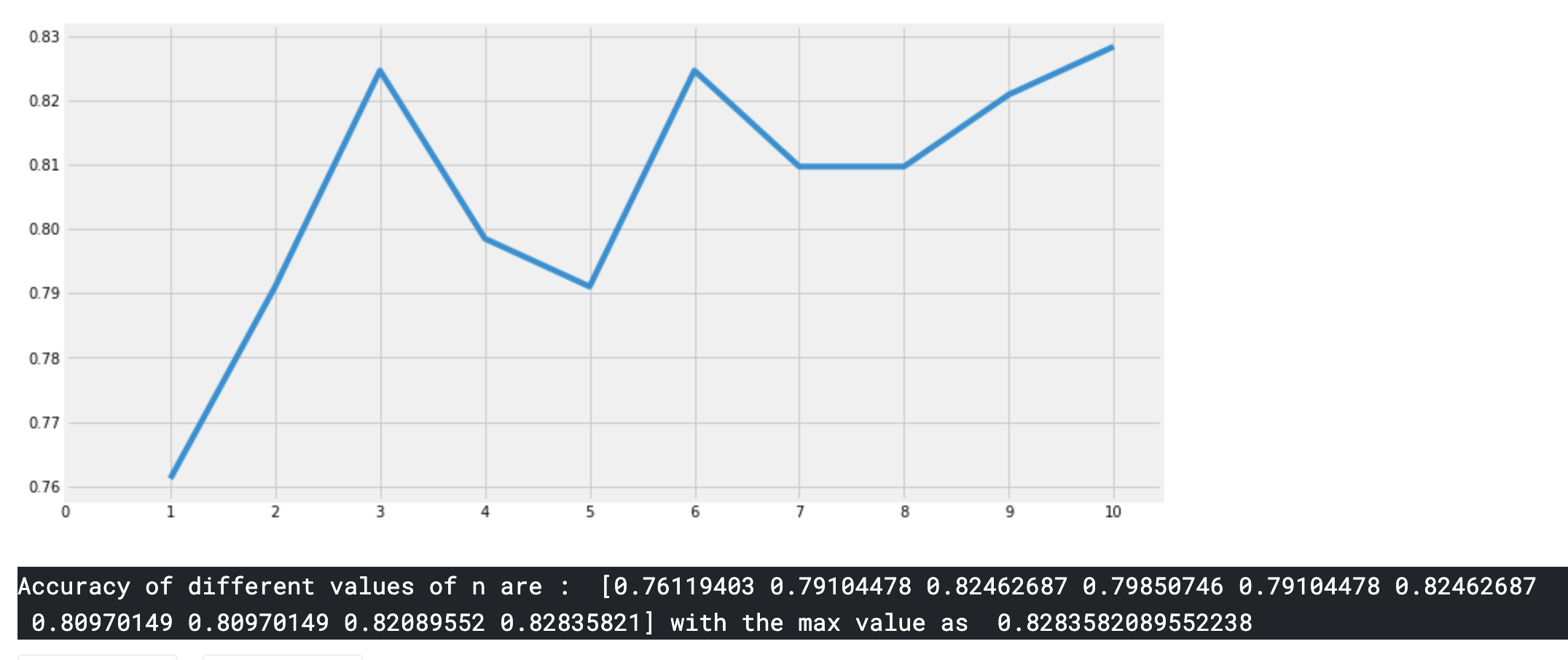
KNN은 n_neighbours attribute값에 따라 정확도가 달라진다. 값을 바꿈에 따라 정확도가 어떻게 변화는지 알아본다
a_index=list(range(1,11))
a=pd.Series()
x=[0,1,2,3,4,5,6,7,8,9,10]
for i in list(range(1,11)):
model=KNeighborsClassifier(n_neighbors=i)
model.fit(train_X,train_Y)
prediction=model.predict(test_X)
a=a.append(pd.Series(metrics.accuracy_score(prediction,test_Y)))
plt.plot(a_index,a)
plt.xticks(x)
fig=plt.gcf()
fig.set_size_inches(12,6)
plt.show()
print('Accuracy of different values of n are : ',a.values,'with the max value as ',a.values.max())n_neighbors가 증가함에 따라 정확도도 올라가는 것을 알 수 있다.
Gaussian Naive Bayes
model=GaussianNB()
model.fit(train_X,train_Y)
prediction6=model.predict(test_X)
print('Accuracy of the NaiveBayes is ',metrics.accuracy_score(prediction6,test_Y))정확도는 81%정도 나온다

Random Forest
model=RandomForestClassifier(n_estimators=100)
model.fit(train_X,train_Y)
prediction7=model.predict(test_X)
print('Accuracy of the Random Forest is ',metrics.accuracy_score(prediction7,test_Y))정확도는 82%정도 나온다

모델의 정확성은 어떤 Classifier를 쓰는 것도 있지만, train데이터와 test데이터가 변화면 정확성도 달라지는데, 이러한 것을 극복하기 위해 Cross Validation을 사용한다.
* 해당 타이타닉 notebook은 Kaggle의https://www.kaggle.com/ash316/eda-to-prediction-dietanic분석을 그대로 따라하면서 나름대로 정리한 부분임을 밝혀둔다.
반응형



