반응형
타이타닉 데이터 분석 및 머신러닝 적용 목차
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #1 데이터 내용 및 객실등급(Pclass), 성별(Sex)확인
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #2 나이(Age)와 탑승위치(Embarked) 확인
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #3 형제자매,배우자(SipSp) 확인
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #4 데이터 정리 및 Feature Engineering
- [머신러닝 기초] 타이타닉 생존율 데이터 가공 - Machine Learning을 위한 데이터 처리 방법
- [머신러닝 기초] 타이타닉 생존율 모델링 - Predictive 모델링
- [머신러닝 기초] 타이타닉 생존율 분석 - Cross Validation
- [머신러닝 기초] 타이타닉 생존율 모델링 최적화 - 앙상블(Ensemble)
앞에서 살펴본 데이터를 정리를 해보면
- Sex : 여성의 생존율이 남성에 비해 높다
- Pclass : 1등급 객실의 승객의 생존율이 높고, 3등급 객실의 승객은 생존율이 많이 낮다. 특히 여성의 경우 1등급 객실의 여성승객은 생존율이 100%에 가깝다.
- Age : 어린 아이의 경우 생존율이 가장 높고, 15~35세 승객은 많이 사망한 것을 알 수 있다.
- Embarked : C지역에서 생존자들의 확율이 높다는 것을 알 수 있다.
- Parch+SibSp : 1~2명의 가족을 가진 승객과 1~3명의 부모자식을 가진 승객의 생존율이 높다.
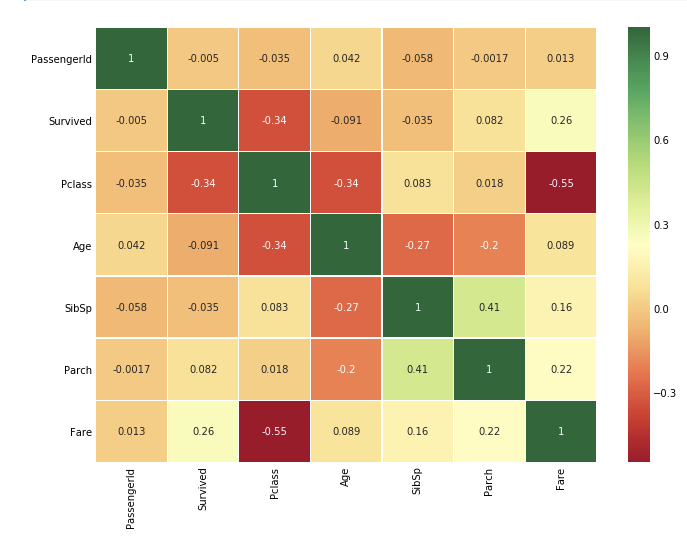
데이터에 대한 상관관계를 heatmap을 통해 살펴본다
sns.heatmap(data.corr(),annot=True,cmap='RdYlGn',linewidths=0.2)
fig=plt.gcf()
fig.set_size_inches(10,8)
plt.show()상관관계는 하나의 feature가 다른 feature와 연관이 될 때, Positive가 될 경우 해당 feature들은 비슷하다라고 판단이 된다. Parch와 SibSp의 관계가 0.41로 높은 Positive를 보이고 있고 다른 관계들은 크게 관계가 없어 보이기 때문에 전체 feature로 분석을 한다.
Feature Engineering
Age의 경우에는 연속된 수로 되어 있기 때문에 Machine Learning 모델에서는 적합하지 않다. 그래서 Age를 구간으로 나누어서 Machine Learning에서 판단할 수 있도록 정해야 한다.
나이를 구간으로 나누어서 16세 이하, 32세 이하, 48세 이하, 64세 이하, 이상으로 구분한다.
data['Age_band']=0
data.loc[data['Age']<=16,'Age_band']=0
data.loc[(data['Age']>16)&(data['Age']<=32),'Age_band']=1
data.loc[(data['Age']>32)&(data['Age']<=48),'Age_band']=2
data.loc[(data['Age']>48)&(data['Age']<=64),'Age_band']=3
data.loc[data['Age']>64,'Age_band']=4
data.head(2)승객별로 Age_band항목에 해당되는 연령에 맞게 구간을 설정한다.

전체 승객의 Age_band를 확인한다.
data['Age_band'].value_counts().to_frame().style.background_gradient(cmap='summer')1구간(16세 이상 32세 이하)에 있는 승객이 가장 많은 것을 알 수 있다.

Factor차트로 객실별로 생존율과 나이 구간에 대해 확인한다.
sns.factorplot('Age_band','Survived',data=data,col='Pclass')
plt.show()나이가 어린 band구간에 있는 승객의 생존율이 높은 것을 알 수 있다.

가족수와 혼자 탑승한 승객에 대한 Feature
가족의 크기를 구하기 위해서 Parch와 SibSp를 더한 다음 0인 승객은 Alone으로 표시하고 생존율을 확인한다.
data['Family_Size']=0
data['Family_Size']=data['Parch']+data['SibSp']
data['Alone']=0
data.loc[data.Family_Size==0,'Alone']=1
f,ax=plt.subplots(1,2,figsize=(18,6))
sns.factorplot('Family_Size','Survived',data=data,ax=ax[0])
ax[0].set_title('Family_Size vs Survived')
sns.factorplot('Alone','Survived',data=data,ax=ax[1])
ax[1].set_title('Alone vs Survived')
plt.close(2)
plt.close(3)
plt.show()가족수는 3명인 승객이 가장 생존율이 높으며 혼자인 경우는 생존율이 낮은 것을 알 수 있다.

Factor차트를 통해 혼자인 경우와 생존율을 성별, 객실 등급에 따라 구해본다.
sns.factorplot('Alone','Survived',data=data,hue='Sex',col='Pclass')
plt.show()객실등급이 높고 여성의 경우는 혼자와 상관없이 생존율이 높은 반면 객실등급이 낮고 혼자인 남성의 경우 사망율이 높은 것을 알 수 있다.

Ticket 가격에 따른 분석
Ticket 가격 역시 연속적으로 이어지는 값이기 때문에 Age와 같이 구간을 정해 분석한다.
data['Fare_Range']=pd.qcut(data['Fare'],4)
data.groupby(['Fare_Range'])['Survived'].mean().to_frame().style.background_gradient(cmap='summer_r')pandas의 qcut은 값에 따라 split하거나 arrange를 해준다. 4개의 구간으로 ticket 가격을 나누고 생존율을 확인한다.
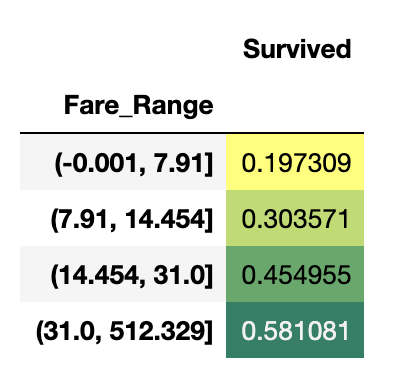
위에 보는 것 처럼 티켓 비용이 클 수록 생존율이 높은 것을 알 수 있으며, 그것을 가지고 Age_band에서 한 것 처럼 encoding한다.
data['Fare_cat']=0
data.loc[data['Fare']<=7.91,'Fare_cat']=0
data.loc[(data['Fare']>7.91)&(data['Fare']<=14.454),'Fare_cat']=1
data.loc[(data['Fare']>14.454)&(data['Fare']<=31),'Fare_cat']=2
data.loc[(data['Fare']>31)&(data['Fare']<=513),'Fare_cat']=3Factor차트로 위에서 구분한 Ticket 가격 구간에 대한 생존율을 성별로 살펴보면 티켓가격이 높고 여성의 경우 생존율이 높은 것을 알 수 있다.
sns.factorplot('Fare_cat','Survived',data=data,hue='Sex')
plt.show()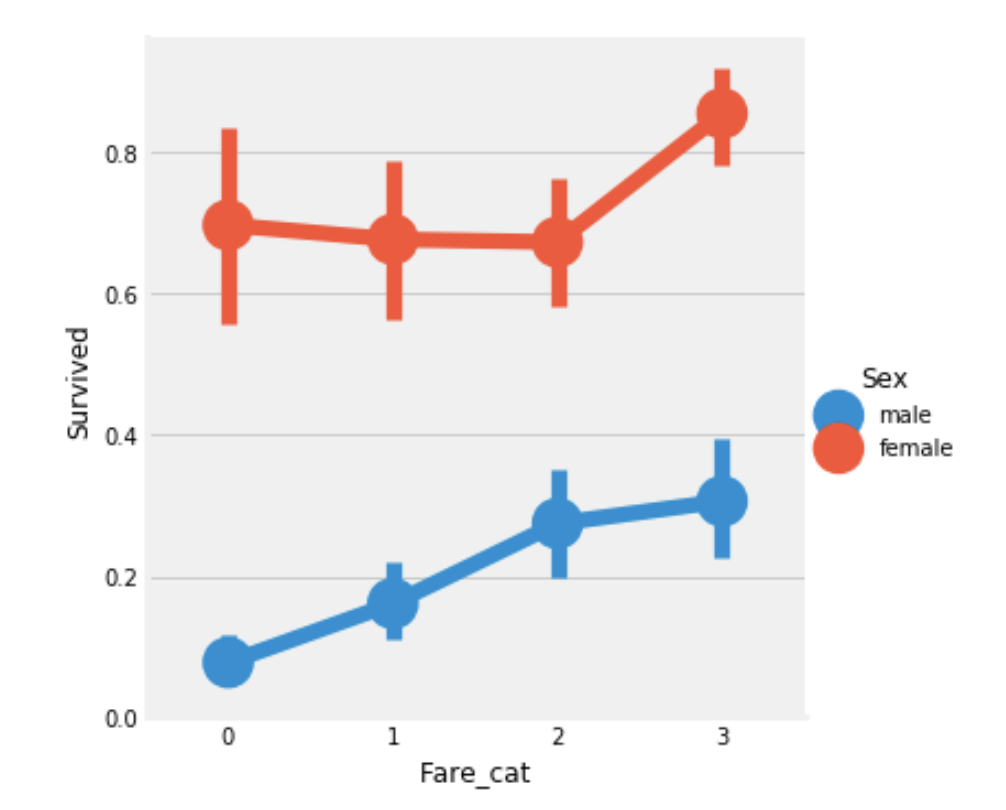
* 해당 타이타닉 notebook은 Kaggle의https://www.kaggle.com/ash316/eda-to-prediction-dietanic분석을 그대로 따라하면서 나름대로 정리한 부분임을 밝혀둔다.
반응형



