반응형
머신러닝을 시작할 때 많이 참조하는 타이타닉 생존율 분석을 통해서 어떻게 머신러닝을 사용할 수 있고, 데이터는 어떻게 가공하고 분석하는지, 머신러닝 모델은 어떻게 사용하는지 등을 초보자 입장에서 따라해보는 포스트이다.
서론으로 들어가면 타이타닉 침몰사고 시 살아남은 사람들에 대한 데이터를 가지고 머신러닝을 통해 생존율을 파악해보는 것이 목적이며, 어떤 승객이 어떤 조건에서 어떻게 살아 남는 확율을 가질 수 있는지를 분석해본다.

타이타닉 데이터 분석 및 머신러닝 적용 목차
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #1 데이터 내용 및 객실등급(Pclass), 성별(Sex)확인
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #2 나이(Age)와 탑승위치(Embarked) 확인
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #3 형제자매,배우자(SipSp) 확인
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #4 데이터 정리 및 Feature Engineering
- [머신러닝 기초] 타이타닉 생존율 데이터 가공 - Machine Learning을 위한 데이터 처리 방법
- [머신러닝 기초] 타이타닉 생존율 모델링 - Predictive 모델링
- [머신러닝 기초] 타이타닉 생존율 분석 - Cross Validation
- [머신러닝 기초] 타이타닉 생존율 모델링 최적화 - 앙상블(Ensemble)
캐글에서 제공해주는 데이터를 Import하고 어떤 데이터가 있는지 확인한다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('fivethirtyeight')
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
data=pd.read_csv('../input/titanic/train.csv')
data.head()데이터는 생존(Survived), 객실등급(Pclass), 이름, 성별, 나이, 형제와배우자(SibSp), 자식과부모(Parch), 티켓, 요금, Cabin, 탑승한곳(Embarked)로 구성되어 있다.

데이터중에 값이 없는 것이 있는지 확인한다. 데이터에 값이 없으면 나중에 분석을 하기 위해 오차가 날 확율이 높다.
data.isnull().sum()Age와 Cabin에 비어 있는 데이터가 많은 것을 확인 할 수 있다.

matplotlib를 이용하여 생존자의 수를 확인한다.
f,ax = plt.subplots(1,2,figsize=(20,8))
data['Survived'].value_counts().plot.pie(explode=[0,0.1], autopct='%1.1f%%',ax=ax[0],shadow=True)
ax[0].set_title('Survived')
ax[0].set_ylabel('')
#print(ax[1])
sns.countplot('Survived',data=data,ax=ax[1])
ax[1].set_title('Survived')
plt.show()Survived 가 1이 생존자를 표시함. 대략 38.4%가 생존했으며 300명 이상이 생존하고, 600명 가까이 사망한 것을 알 수 있다.

성별과 생존자에 대해 확인을 해본다.
data.groupby(['Sex','Survived'])['Survived'].count()여성은 생존자 233명 사망자 81명, 남성은 생존자 109명, 사망자 468명으로 확인된다.

성별로 생존자의 비율을 확인해보고, 성별별로 생존자와 사망자 숫자를 확인한다.
f,ax = plt.subplots(1,2,figsize=(18,8))
data[['Sex','Survived']].groupby(['Sex']).mean().plot.bar(ax=ax[0])
ax[0].set_title('Survived VS Sex')
sns.countplot('Sex',hue='Survived',data=data,ax=ax[1])
ax[1].set_title('Sex:Survived VS Dead')
plt.show성별로 여성이 70% 이상 더 생존한 것을 알 수 있고, 성별로 남성은 100명 정도 생존, 400명 이상 사망, 여성은 200명 이상 생존, 100명 이하 사망을 그래프로 볼 수 있다.

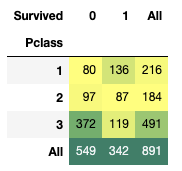
Crosstab을 통해 객실 등급(Pclass)에 따른 생존자를 확인해본다.
pd.crosstab(data.Pclass,data.Survived,margins=True).style.background_gradient(cmap='summer_r')1등급 객실이 제일 생존자가 많은 것을 알 수 있다. 136명
객실 별 생존자를 그래프로 확인해본다.
f,ax = plt.subplots(1,2,figsize=(18,8))
data['Pclass'].value_counts().plot.bar(color=['#CD7F32','#FFDF00','#D3D3D3'],ax=ax[0])
ax[0].set_title('Number of Passengers By Pclass')
ax[0].set_ylabel('Count')
sns.countplot('Pclass',hue='Survived',data=data,ax=ax[1])
ax[1].set_title('Pclass:Survived vs Dead')객실별로 3등급 객실에 사람이 제일 많았으며 1등급 객실이 두번째, 2등급 객실이 제일 적었다. 객실별로 생존자는 1등급 객실이 제일 많았으며 3등급 객실이 사망자가 제일 많았다. (역시 돈을 많이 벌어서 1등급 객실에 타야 하는듯..)

Crosstab으로 이제 객실과 성별에 대해 생존자 수를 확인해본다.
pd.crosstab([data.Sex,data.Survived],data.Pclass,margins=True).style.background_gradient(cmap='summer_r')전체 생존자는 1등급 객실이 제일 많았으며, 여성의 생존자가 많은 것을 확인할 수 있다. 슬프게도 3등급 객실의 남성이 제일 사망자가 많은 것을 확인 할 수 있다.

Factorplot을 통해 객실등급과 생존자의 관계를 성별로 나누어 한번에 살펴본다.
sns.factorplot('Pclass','Survived',hue='Sex',data=data)1등급 객실에 승선한 것이 가장 생존율이 높은 것으로 보이며 특히 여성의 비율이 높다.

승객들의 나이를 확인해본다. 제일 어린 사람, 최고연장자, 평균 나이를 알아본다.
print('Oldest Passenger was of:',data['Age'].max(),'Years')
print('Youngest Passenger was of:',data['Age'].min(),'Years')
print('Average Age on the ship:',data['Age'].mean(),'Years')
바이올린 플롯으로 객실과 나이에 대한 생존자 비율, 성별과 나이에 대한 생존자 비율을 살펴본다.
f,ax=plt.subplots(1,2,figsize=(18,8))
sns.violinplot("Pclass","Age",hue="Survived",data=data,split=True,ax=ax[0])
ax[0].set_title('Pclass and Age VS Survived')
ax[0].set_yticks(range(0,110,10))
sns.violinplot("Sex","Age",hue="Survived",data=data,split=True,ax=ax[1])
ax[1].set_title('Sex and Age VS Survived')
ax[1].set_yticks(range(0,110,10))
plt.show()객실별로 1등급 객실의 30~40대 사이가 가장 생존자가 많아 보이고, 30대 남성과 여성이 생존자가 많은 것을 확인 할 수 있다.

* 해당 타이타닉 notebook은 Kaggle의 https://www.kaggle.com/ash316/eda-to-prediction-dietanic분석을 그대로 따라하면서 나름대로 정리한 부분임을 밝혀둔다.
반응형



